The following is a blog post I wrote for the SQream Technologies blog.
![]() Data processing and gathering has come a long way since the initial automation improvements in the late 19th century. Despite a plethora of academic research, we have yet to see a market ready GPU based SQL database. Until now.
Data processing and gathering has come a long way since the initial automation improvements in the late 19th century. Despite a plethora of academic research, we have yet to see a market ready GPU based SQL database. Until now.
Humble beginnings
The mechanized database solution invented by Herman Hollerith of the US Census pioneered the way for data collection and processing. His census tabulating machine shaved months off the US census processing time, from the 13 years time projected.
Using a clock-like counting device to display the results, when a predetermined position on a specially designed punch-card was scanned, the counter’s electromagnet moved the clock hand one point forward. The operator of the machine would place a card in the reader, pull down a lever and then remove the card once the holes had been counted.
We can compare the successive stages of punched-card processing to fairly complex calculations in SQL.
Each stage can compare to this full SQL query:
SELECT (filter columns) WHERE (filter cards, or “rows”).
By the end of all cycles, we can liken the result to the previous query, with the addition of a GROUP BY clause for the totals and counts.

Hollerith’s tabulating machine. Source: IBM
In fact, Hollerith’s machine was so successful, it launched his company into what we know today as IBM. IBM continued developing these machines and they were still used well into the 1950s, even when electronic computers had already been invented.
This revolution brought on by punch cards, proliferated into many different areas outside of the US government. Many corporations used this to redesign their administration. IBM was naturally the leader in this form of enterprise tabulating.
The advent of the relational model and SQL
In 1970, Edgar Codd, an employee at IBM’s research laboratory published his revolutionary relational database model research paper titled “A Relational Model of Data for Large Shared Data Banks“.
In this relational model, all data is represented in tuples, grouped into relations. This means that by a simple organization, the data could be used as a tool for complex querying – providing valuable hidden analytics.
Like many other revolutionary ideas, the relational model wasn’t easy to push forward. IBM chose to focus on its existing product named IMS/DB running on the then ubiquitous System/360. It was already making the company a lot of money. Unfazed, he proceeded to show his new model to IBM customers who in turn pressured IBM into including it in their upcoming System R.
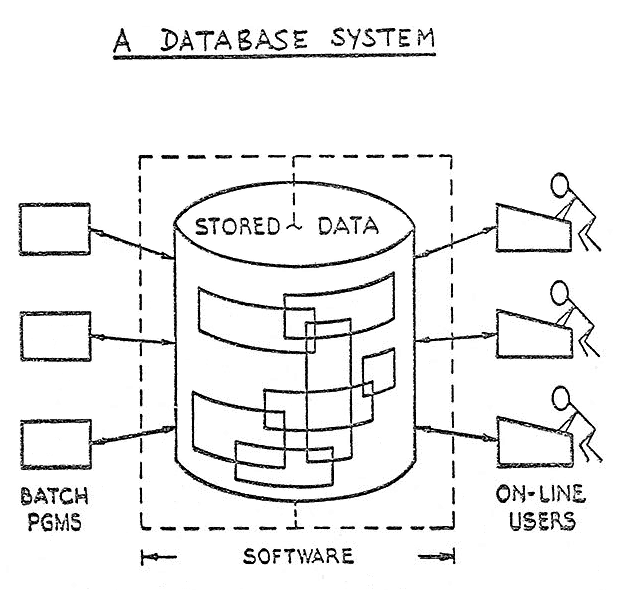
“A database – illustrated”. Source: IBM
IBM, still not keen on cutting off its IMS/DB cash cow isolated the System R development team from Codd. The development team came up with an alternative representation known as SEQUEL as early as 1974.
By separating the data from the applications accessing the data and enabling the manipulation of the information through an English like query language, the hidden analytics could be extracted through construction of logic statements in the relational model.
Despite its drawbacks, SEQUEL was so vastly superior to other existing non-relational database implementations, that it was eventually replicated into Larry Ellison’s Oracle Database using only pre-launch whitepapers.
Oracle Database was eventually first to market in 1979, before IBM’s SQL/DS in 1981 which later became DB2.
Alternatives to SQL
Today, SQL and the relational model are the most widely used computer languages for databases, despite newcomers like NoSQL and clustered database solutions like Hadoop.
For many startups, NoSQL might be a good idea because it allows the fast collection of a lot of data, even when you don’t know when and if it’ll be used. Further down the line, when the company matures, the complexity of migrating to structured data might become a big expense in time, manpower and money.
Because NoSQL is non-relational, most implementations do not provide features like persistence, transactions or durability contrary to the prevailing practice among relational database systems.
Despite the attraction it generates, SQL continues to be a mainstay for big corporations, gaining even more adoption in the big data market.
![]()
![]()

In comes the GPU (Graphic Processing Unit)
Over the past decade, graphics processors have made leaps and bounds and have been found to add significant value in both research and industry, where better performance in data intensive operations is needed.
Because of its structure, the GPU enables a single ‘instruction’ to be performed on huge chunks of data simultaneously (SIMD, Single Instruction, Multiple Data), compared to a general purpose CPU which typically has a smaller scale implementation of SIMD.
| GPU Architecture | CPU Architecture |
 |
 |
Think of the GPU as a coin press machine, which can punch out 100 coins with one operation from a single sheet of metal, whereas a CPU is a coin press which can punch out 10 coins at a time from a strip of metal. While the CPU might have a faster ‘time between punches’, it also requires a faster feed rate of metal strips as well. This is the key difference between the GPU and CPU. The GPU is throughput oriented, while the CPU is latency oriented.
The GPU is therefore well suited for operations that perform the same instruction on large amounts of data at once.
| GPU Large Scale SIMD | CPU Small Scale SIMD |
 |
 |
A plethora of research activity
A lot of research has been made in regards to the usage of the GPU’s massive parallelism as an accelerator for database queries.
Due to the complexity of building an entire database, most of the research is focused on speeding up the processing by keeping the database memory entirely in the RAM, and not in the system’s slower storage. This enables a 100 times speed increase in the heavy lifting performed on the GPU compared to the CPU and removes the need to move the data from the storage to the GPU.
As a direct result from these mostly academic researches, some real-world solutions have been designed, offering GPU-aware plugins to empower existing SQL database management solutions (i.e. PGStrom for PostgreSQL). However, these solutions are only partial, because they use many components that are not meant to handle the parallelism enabled by the GPU.
The difficulty in designing a good GPU-based relational database stems from the desire to fully exploit the GPU. This requires a rethinking of the entire database architecture from the ground up – how the data is stored, how the query plan is generated to handle the parallelism and more importantly, how the data is moved from the main memory to the GPU.

Source: http://xkcd.com/664/
Where SQream Technologies fits in
By writing an entire system from the ground up, SQream has managed to gain fine-grained control over both the parallelism and the data storage.
Our entire system was built from scratch, from the SQL query parser, to the query planner and compiler and through the storage and compression.
By exploiting a rapid GPU-based compression, we transfer much less data between main memory and GPU memory. This increases the GPU utilization and eliminates the transfer bottleneck. Combining it with Nvidia’s ultra-fast memory throughput has let us push the boundaries of big data analytics, without scaling out to clustered, multi machine setups.
The result is blazingly rapid big data analytics, at a fraction of the cost and power requirements of traditional big data solutions – both clustered and unclustered – while still keeping the familiar standardized SQL syntax.
The future
Future improvements involving direct GPU to memory access are fast becoming a reality. Nvidia’s latest NVLINK technology enables fast inter-GPU access.
These technologies further advance the speed benefits that can be gained by using the GPU for big data processing without adding more power hungry machines. GPUs will become a mainstay in database applications.
This post was originally posted on the SQream Technologies blog
Leave a Reply